
Adversarial Attacks Against ASR Systems via Psychoacoustic Hiding
Lea Schönherr, Katharina Kohls, Steffen Zeiler, Thorsten Holz, and Dorothea Kolossa
Ruhr-Universität Bochum
Introduction
Personal assistants such as Alexa, Siri, or Cortana are widely deployed these days. Such Automatic Speech Recognition (ASR) systems can translate and even recognize spoken language and provide a written transcript of the spoken language. Recent advances in the fields of deep learning and big data analysis supported significant progress for ASR systems and have become almost as good at it as human listeners.
In this work, we demonstrate how an adversary can attack speech recognition systems by generating an audio file that is recognized as a specific audio content by a human listener, but as a certain, possibly totally different, text by an ASR system:
More audio examples can be found at the end of the articel.
These so-called adversarial examples exploit the fact that ASR systems based on machine learning have some wiggle room that an attacker can exploit: by adding some distortions, we can mislead the algorithm into recognizing a different sentence. The main contribution of our work is to demonstrate that we can generate the noise in such a way that it is almost completely hidden from human listeners. For this purpose, we take advantage of a psychoacoustic model of human hearing, describing the masking effects of human perception, which is also used for MP3 decoding.

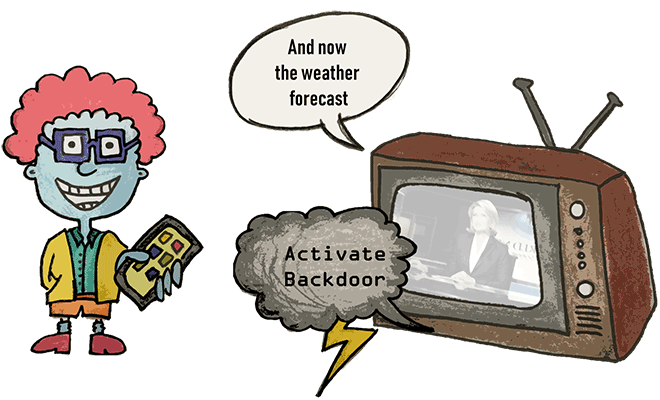
Why (and how) can we attack ASR systems?
- Neural Networks: ASR systems can recognize spoken words using so-called neural networks. Such networks are inspired by the biological neural systems of animals and humans and allow a computer system to develop a certain capability for a specific task through training.
- Personal Assistants: A personal assistant, like the one you find in your smartphone or computer, helps to trigger functions of your devices just by using your voice. This is nice as long as it is you triggering the functions, but it becomes a problem if an attacker has the same capabilities. It gets even worse if you don't hear an attack taking place.
- Psychoacoustics: Human hearing is limited to a certain range of frequencies, amplitudes, and signal dynamics. The field of psychoacoustics addresses such hearing restrictions and provides a rule set for things that humans can and cannot hear. While these rules are used in different fields, e.g., in MP3 music compression, we can also utilize psychoacoustics for our attack to hide noise in such a way that humans (almost) cannot hear it.
ASR Systems
Automatic Speech Recognition (ASR) systems can recognize speech, recently, almost as well as human listeners. We find ASR systems in a variety of modern systems, for example, home automation systems or personal assistants in smartphones. Using different methodologies and technologies from the field of computational linguistics, ASR systems can recognize and even translate spoken languages. Advances in the fields of deep learning and big data have supported recent progress for ASR systems, however, they have also created new vulnerabilities. We can attack speech recognition systems by triggering their actions through imitated voice commands. In this work, we implement an attack that activates ASR systems without being recognized by humans.
We used Kaldi as state-of-the-art ASR system, which consists of three different steps to calculate transcriptions of raw audio:
- Preprocessing Audio Input: This step transforms the raw input data into features that should ideally preserve all relevant information while discarding the unnecessary remainder.
- Neural Network: The DNN uses the feature representation of the audio input to caclulate a representation of words sequences.
- Decoding: The so-called decoder in ASR systems utilizes some form of graph search to find the transcription that best fits the audio input.
Psychoacoustics
Hearing Models
Psychoacoustic hearing thresholds describe masking effects in human acoustic perception. Probably the best-known example for this is MP3 compression, where the compression algorithm uses a set of computed hearing thresholds to find out which parts of the input signal are imperceptible for human listeners. By removing those parts, the audio signal can be transformed into a smaller but lossy representation, which requires less disk space and less bandwidth to store or transmit.

How to exploit this
MP3 compression depends on an empirical set of hearing thresholds that define how dependencies between certain frequencies can mask, i.e., make imperceptible, other parts of an audio signal. We utilize this psychoacoustic model for our manipulations, i.e., all changes are hidden in the inperceptible parts of the audio signal..
Attack
Attack Procedure
For the attack, in principle, we use the very the same algorithm as for the training of neural networks. The algorithm is based on gradient descent, but instead of updating the parameters of the neural network as for training, the audio signal is modified. We use the hearing thresholds to avoid changes in easily perceptible parts of the audio signal.
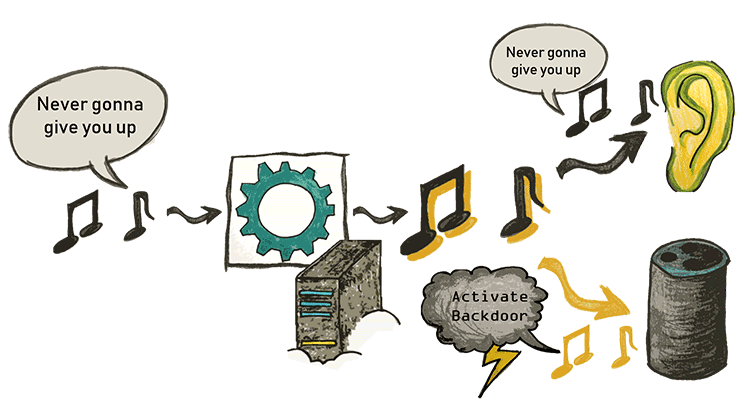
Results
In general it is possible to hide any transcription in any audio file with a success rate of nearly 100 %.
As an example, we have some audio clips, which are modified with the described algorithm:
Audio Examples
| Original | Modified | Noise | |
|---|---|---|---|
| Speech | |||
| Music | |||
| Birds | |||
| Speech |